Pytorch Loss优化
Pytorch Loss优化
问题引入
考虑这么一个网络的优化: 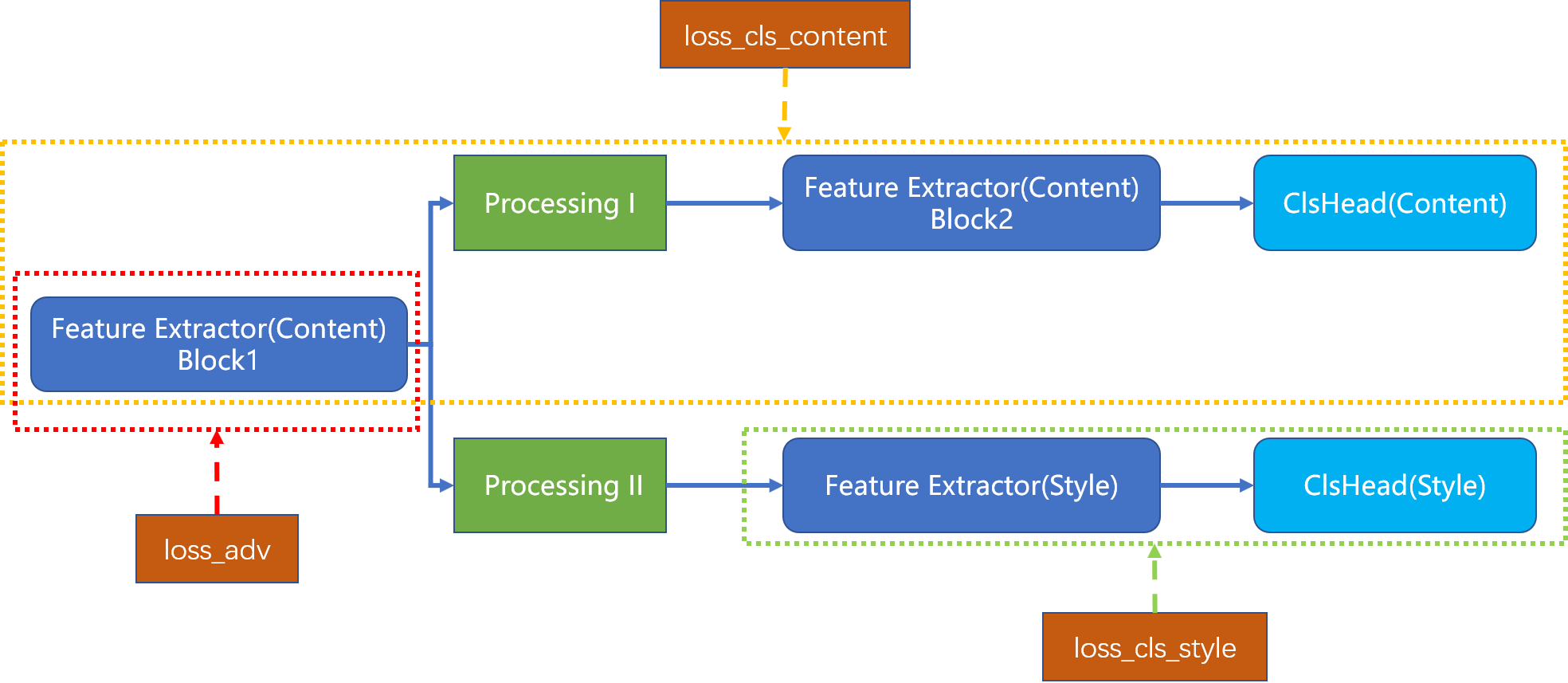 整个网络由3个loss优化(
整个网络由3个loss优化(loss_cls_content, loss_adv, loss_cls_style),其中loss_cls_content只优化Feature Extractor(Content) Block1, Feature Extractor(Content) Block1, ClsHead(Content)(黄色虚线框框住的模块)、loss_adv只优化Feature Extractor(Content) Block1(红色虚线框框住的模块)、loss_cls_style只优化Feature Extractor(Content) Block2, ClsHead(Style)(绿色虚线框框住的模块)。 ## 如何进行梯度回传 定义三个优化器optimizer_content, optimizer_style, optimizer_adv,分别优化三个虚线框内模块的参数;
容易想到这么一种优化方法: # 如果不考虑使用detach()进行模块隔绝(实际上detach对这个网络的优化也无能为力),三个loss在回传过程中都会影响到不希望影响到的模块
# 考虑使用三个优化器,只优化对应模块的参数,三个loss分别回传,优化前都会进行梯度归零、回传后马上更新权值,即可达到想要的优化效果
optimizer_style.zero_grad()
loss_cls_style.backward(retain_graph=True)
optimizer_style.step()
optimizer_adv.zero_grad()
loss_adv.backward(retain_graph=True)
optimizer_adv.step()
optimizer_content.zero_grad()
loss_cls_content.backward()
optimizer_content.step()
这是因为每个loss回传后都需要及时更新对应权值,否则会被梯度归零而无法优化,这也导致了权值已经不同于loss计算时对应的权值,而梯度计算时一般都需要用到权值,也就是modified by an inplace operation
新版本pytorch的backward()加入了inputs参数,该参数能确保loss在回传时只更新特定权值的梯度,于是有了这么一种优化方式: optimizer_style.zero_grad()
optimizer_adv.zero_grad()
optimizer_content.zero_grad()
loss_cls_style.backward(retain_graph=True, inputs=style_params)
loss_adv.backward(retain_graph=True, inputs=adv_params)
loss_cls_content.backward(inputs=content_params)
optimizer_content.step()
optimizer_style.step()
optimizer_adv.step()